Self-Learning AI Model Learns from Patient Data to Design Novel Clinical Trials
Technical summary
Unstructured learning problems without well-defined rewards are unsuitable for current reinforcement learning (RL) approaches. Action-derived rewards can allow RL agents to fully explore state and action trade-offs in scenarios that require specific outcomes yet are unstructured by external reward. Clinical trial dosing choice is an example of such a problem. This study led by Dr. Shah reported the successful formulation of clinical trial dosing choice as an RL problem using action-based rewards and learning of dosing regimens to reduce mean tumor diameters (MTD) in patients undergoing simulated temozolomide (TMZ) and procarbazine, 1-(2-chloroethyl)-3-cyclohexyl-l-nitrosourea, and vincristine (PCV) chemo- and radiotherapy clinical trials. The use of action-derived rewards as partial proxies for outcomes is described for the first time. Novel dosing regimens learned by an RL agent in the presence of action-derived rewards achieve significant reduction in MTD for cohorts and individual patients in simulated TMZ and PCV clinical trials while reducing treatment cycle administrations and dosage concentrations compared to human-expert dosing regimens. This approach can be easily adapted for other learning tasks where outcome-based learning is not practical.
Glioblastoma (brain tumors) background: Glioblastoma is an aggressive type of cancer that can occur in the brain or spinal cord. A hard-hitting treatment typically involves combining surgery with radiation therapy and chemotherapy, which is necessary to combat the aggressive nature of a glioblastoma. Chemo-and Radiotherapy Treatments (CRT) may slow the progression of cancer and reduce signs and symptoms, but are unable to cure the disease. Survival rates are low (about 14-18 months) and only about 10% of patients live five years or longer. CRTs are often given as a combination of drugs. Procarbazine, 1-(2-chloroethyl)-3-cyclohexyl-l-nitrosourea, and Vincristine (PCV) is triple drug chemotherapy for glioblastomas and can be toxic for the patients. Temozolomide (TMZ), is less toxic, has shown greater efficacy when compared to radiotherapy alone, in the treatment of glioblastoma. There is significant and urgent need for novel CRT dosing regimens in human subjects to optimize for maximum therapeutic benefit for patients while reducing toxicity.
Reinforcement learning background: Reinforcement learning (RL) is an area of machine learning and AI inspired by behaviorist psychology. RL agents can self-learn how to solve complex tasks in a relatively unstructured environment so as to maximize some notion of cumulative rewards and reduce penalties set by human programmers. Reward functions in RL domains are typically derived from a measure that is external to the chosen representation of the states (data) and actions (steps) used for the self-training algorithm. Using RL to solve tasks without readily accessible external scalar outcomes is a relatively unexplored field, as many currently studied domains have well-defined outcomes and associated rewards as part of their definitions.
Clinical trials background: Clinical trials to evaluate new drugs, therapies, and vaccines are among the most complex experiments performed in medicine. Nearly half of phase 2 and phase 3 trials fail. For oncology trials, the failure rate rises to two-thirds. A common theme is the difficulty of predicting clinical results in a wide patient base given limited knowledge of key parameters which need to be considered to test candidate molecules, eliminate adverse events, and identify the drugs half maximal inhibitory concentration. Optimal CRT dosing for patients enrolled in glioblastoma clinical trials thus provides one example of an open-ended problem characterized by complex interactions between different drug properties, dosage and timing of administrations (actions), and effects on tumors (state) and where survival (outcomes) may not be available.
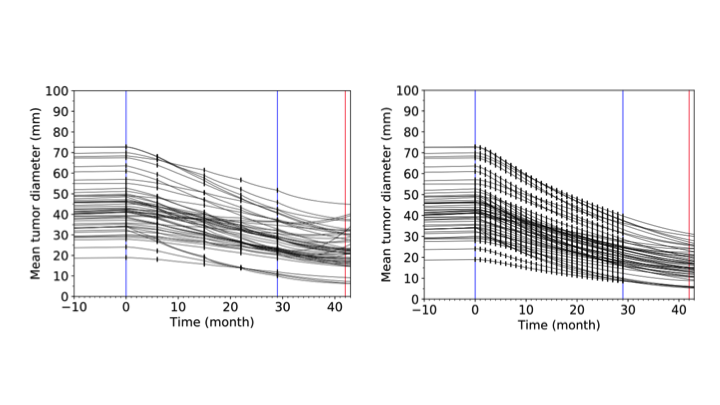
The reinforcement learning agent administers fewer Temozolomide (TMZ) doses (left panel) compared to corresponding human expert policies for the same patients (right panel).
Credit:
Pratik Shah
Q and A
-
What is the value proposition of this work?
In several constrained settings such as clinical trials and treatment for chronic conditions, the relationship between current state of the patient’s disease and treatment choices representations that play a crucial role in influencing outcomes, may be unavailable to the RL agent for learning until later. Devising suitable non-trivial reward functions for self-learning AI algorithms that learn the contribution from such actions and states to the desired outcomes is a promising approach to solve classes of problems in clinical trials and medicine.
-
What are key findings from this work?
The chemo-and-radiotherapy dosing regimens designed by our self-learning AI models achieved significant reduction in mean tumor diameters for groups and single patients in simulated glioblastoma trials, while reducing drug concentrations and administrations, compared to treatment regimens currently used by human experts. Models communicated from this study can also be useful for exploring the possibilities and ultimately designing novel dosing regimen for other clinical trials and medication-dosing scenarios where there is significant need to reduce toxicity while treating patients. These machine learning models learn actions (vs. solely outcomes), to maximize rewards and are unique in both the computer science and the clinical world.
-
What is the significance of this work for AI and machine learning research?
In conventionally studied reinforcement learning domains (gaming, etc.), rewards set by human experts solely maximize predetermined external scalar outcomes (maximize score at any cost/actions). In this research, an unorthodox approach (driven by clinical trial needs) where the rewards for the reinforcement learning system were modulated from the action space to achieve reductions in glioblastoma tumor sizes was reported.
-
What is the significance of this work for clinical trials and personalized medicine research?
Traditionally, a uniform dosing regimen is used for groups of patients during clinical trials and therapeutic medicines. But differences in tumor size, medical histories, genetic profiles, and biomarkers can affect how a patient would respond, but these variables are not considered during traditional clinical trial design and other treatments, often leading to poor therapy responses in large populations. The machine learning architecture designed in this study is able to recommend precision medicine based treatments for individual patients.
-
What are the next steps?
Ongoing conversations with regulatory agencies, academic hospitals, foundations, patients and biotechnology companies for additional clinical validation.
MIT News article on this research
Gregory Yauney and Pratik Shah; Proceedings of the 3rd Machine Learning for Healthcare Conference, PMLR 85:161-226, 2018.

Dr. Pratik Shah
Faculty Member
Other Contributors
Gregory Yauney. Cornell.